Using Hadoop to Analyze 32 Million Movie Ratings
A couple weeks ago, I was scrolling through the New York Times’ “The 100 Best Movies of the 21st Century.” Beautifully curated, insider-heavy, and almost completely unfamiliar to me—I’d seen maybe ten. I loved how distinct the list felt, probably because it was built from a small, hand-picked set of votes from people in the film industry. But it made me wonder: what do regular people like? And not just for the last couple decades—what about ever?
Sure, I’m sure lists like that already exist. But I’d also been meaning to play around more with large-scale data processing, and this was a perfect excuse. I found the MovieLens dataset from GroupLens, which has different sizes ranging from 10K all the way up to 32 million real user ratings. I didn’t need distributed processing to work with it, but I wanted an excuse to dive into Hadoop and MapReduce, so this felt like a fun weekend project.
I started small—with the 10K version—so I could design and test my jobs without wasting too much compute. For context: Hadoop is a framework for processing massive datasets in a distributed way using the MapReduce model. You store the data in a distributed file system called HDFS, and MapReduce lets you write programs to crunch through that data in parallel. Hive is basically SQL-on-Hadoop—it lets you write HiveQL queries, which then get converted into MapReduce jobs for you.
Hadoop Ecosystem Diagram: from https://tutorials.freshersnow.com/hadoop-ecosystem-components/
Originally, I considered spinning up a Linux VM with VirtualBox and installing Hadoop manually, just to get a feel for it all. But I decided to go with AWS EMR instead. It’s cleaner, lets you focus more on the job logic than the setup, and it gave me experience working with managed clusters in the cloud.
The data itself was clean and relational—just a few CSVs: one with movie ratings (user_id, movie_id, rating), and one with movie metadata (movie_id, title, genres). Perfect join material. Sure, I could’ve used HiveQL and been done in a few lines, but I wanted to write a MapReduce job myself—to really understand how the mappers, reducers, and combiners work.
userId,movieId,rating,timestamp
1,17,4.0,944249077
1,25,1.0,944250228
1,29,2.0,943230976
1,30,5.0,944249077
1,32,5.0,943228858
movieId,title,genres
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
5,Father of the Bride Part II (1995),Comedy
So I did. I started by loading just the ratings file into HDFS and wrote a mapper that keyed on movie_id and emitted the rating. This was simple enough to set up as a local Maven-built repository, allowing me to export the JAR and deploy it directly on EMR. Then I faced a choice: how do I get the movie metadata into the reducer?
- Option one: only store the ratings in HDFS, and have each reducer query S3 for metadata during its setup phase. That avoids redundant queries in the reduce step, but you’re still relying on external data mid-job, which can be brittle and slow.
- Option two: put both datasets into HDFS and have the mapper treat them differently based on filename or other cues—maybe prefix each line with an “m” for metadata or “r” for ratings. That way, the reducer just waits until it sees both data types for a movie_id, then combines them.
I went with option two. It was cleaner, everything stayed local to HDFS, and it scaled better for larger datasets. Once I had the basic join logic working, I added a combiner to aggregate partial results and reduce shuffle load—a small but meaningful optimization.
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// If the filename ends with ".item", split by pipe
// movie id [0], movie title [1], release date [2], IMDB URL [3]
String filePathString = ((FileSplit) context.getInputSplit()).getPath().toString();
if (filePathString.endsWith(".item")) {
// split the fields by pipe
String[] fields = value.toString().split("\\|");
outputKey = new IntWritable(Integer.parseInt(fields[0]));
outputValue.set("m\t" + fields[1] + "\t" + fields[2] + "\t" + fields[4]);
context.write(outputKey, outputValue);
}
// If the filename ends with ".data", do below
else if (filePathString.endsWith(".data")){
String[] fields = value.toString().split("\t");
outputKey = new IntWritable(Integer.parseInt(fields[1])); // movie id is the second field
outputValue.set("d\t" + fields[2]); // rating is the third field
context.write(outputKey, outputValue);
}
else {
System.err.println("Skipping unrecognized file: " + filePathString);
}
}
public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String meta = null;
int ratingSum = 0;
int numRatings = 0;
for (Text value : values) {
String strValue = value.toString();
// If the value starts with "m", it contains movie metadata
if (strValue.startsWith("m")) {
meta = strValue.substring(2); // Remove "m\t" prefix
}
// If the value starts with "d", it contains rating information
else if (strValue.startsWith("d")) {
String[] parts = strValue.split("\t");
int rating = Integer.parseInt(parts[1]);
ratingSum += rating;
numRatings++;
}
}
if (meta == null) {
// If no metadata was found, we cannot output a valid record
System.err.println("No metadata found for key: " + key.toString());
}
else {
Text outputText = new Text(meta + "\t" + ((double) ratingSum / numRatings) + "\t" + numRatings);
context.write(key, outputText);
System.out.println("Combiner output for key: " + key.toString() + ", value: " + outputText);
}
}
Eventually, I wanted to try the full 32M ratings dataset, but also experiment with HiveQL. So I SSH’d into my EMR cluster’s primary node, copied my files over from S3, and ran hadoop fs -put to load them into HDFS. From there, I wrote a Hive script to create external tables over those files and ran a simple join query. That’s when the magic hit: something that took a dozen Java classes and a pile of logs to debug in Hadoop, I got done in a few lines of HiveQL. And Hive still kicked off MapReduce jobs behind the scenes—I could see them getting spawned and executed. It’s really slick.
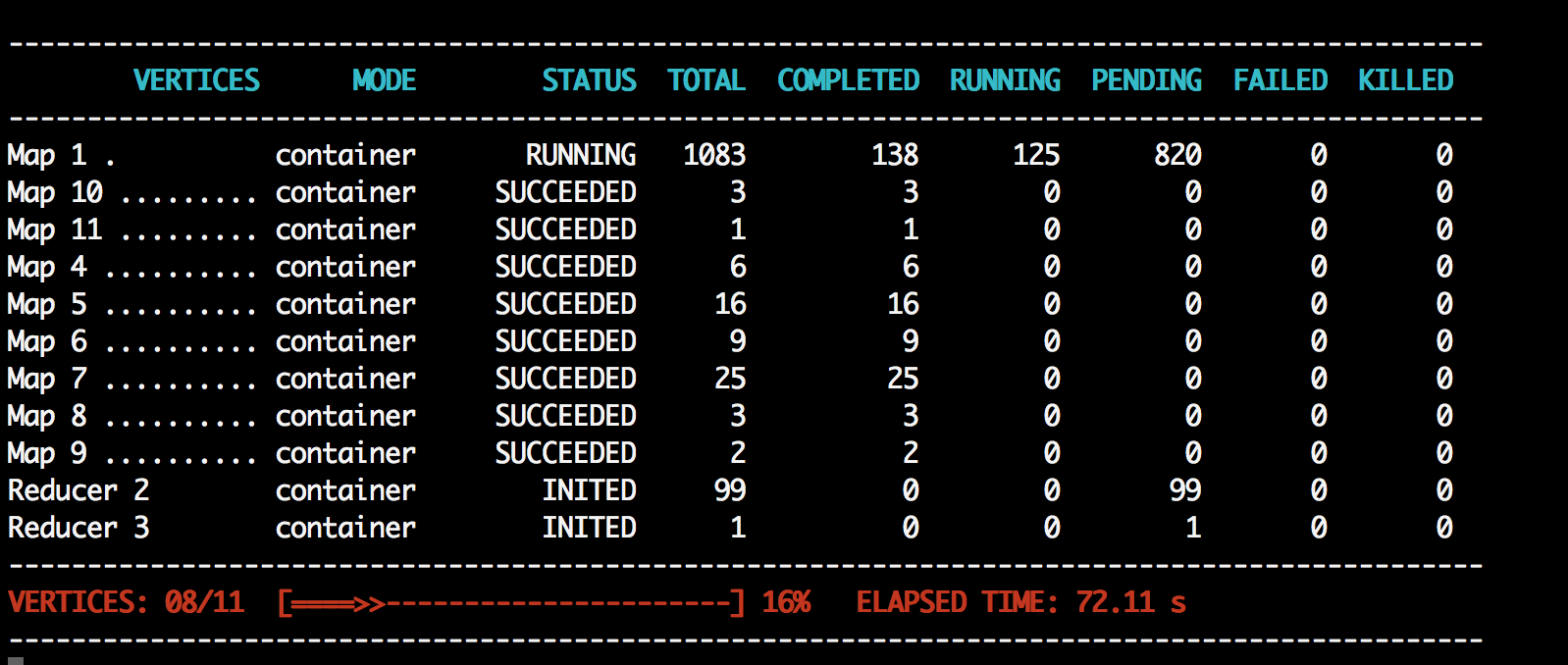
Hive generating a MapReduce Job. Source
Even better: I learned that Hive can directly point to S3 buckets. No aws s3 cp, no hadoop fs -put. Just create your external table and link it to the S3 path. You don’t even need to care where the data lives—HDFS, S3—it abstracts it away. You could go surprisingly far just using Hive with S3, without ever manually touching the distributed file system.
-- Set up the Movie Info table
CREATE TABLE movie (movie_id INT, title STRING, genres STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE
LOCATION 's3://ratings-nshyamsunder-2/input/film';
-- Set up the Ratings table
CREATE EXTERNAL TABLE rating (user_id INT, item_id INT, score INT, rated_at BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://ratings-nshyamsunder-2/input/rating';
-- Perform the JOIN, write out the results
INSERT OVERWRITE LOCAL DIRECTORY '/user/hadoop/export_dir' ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT m.movie_id, m.title, AVG(r.score) AS average_score, COUNT(*) AS review_count
FROM movie m INNER JOIN rating r ON m.movie_id = r.item_id
GROUP BY m.movie_id, m.title HAVING COUNT(*) > 200
ORDER BY average_score DESC LIMIT 200;
After pulling my final results, I wrapped up the project by building a little frontend using Vite and React, styled it up with Tailwind CSS, and posted the results online. You can check it out here: https://movielensdb-hadoop.vercel.app/
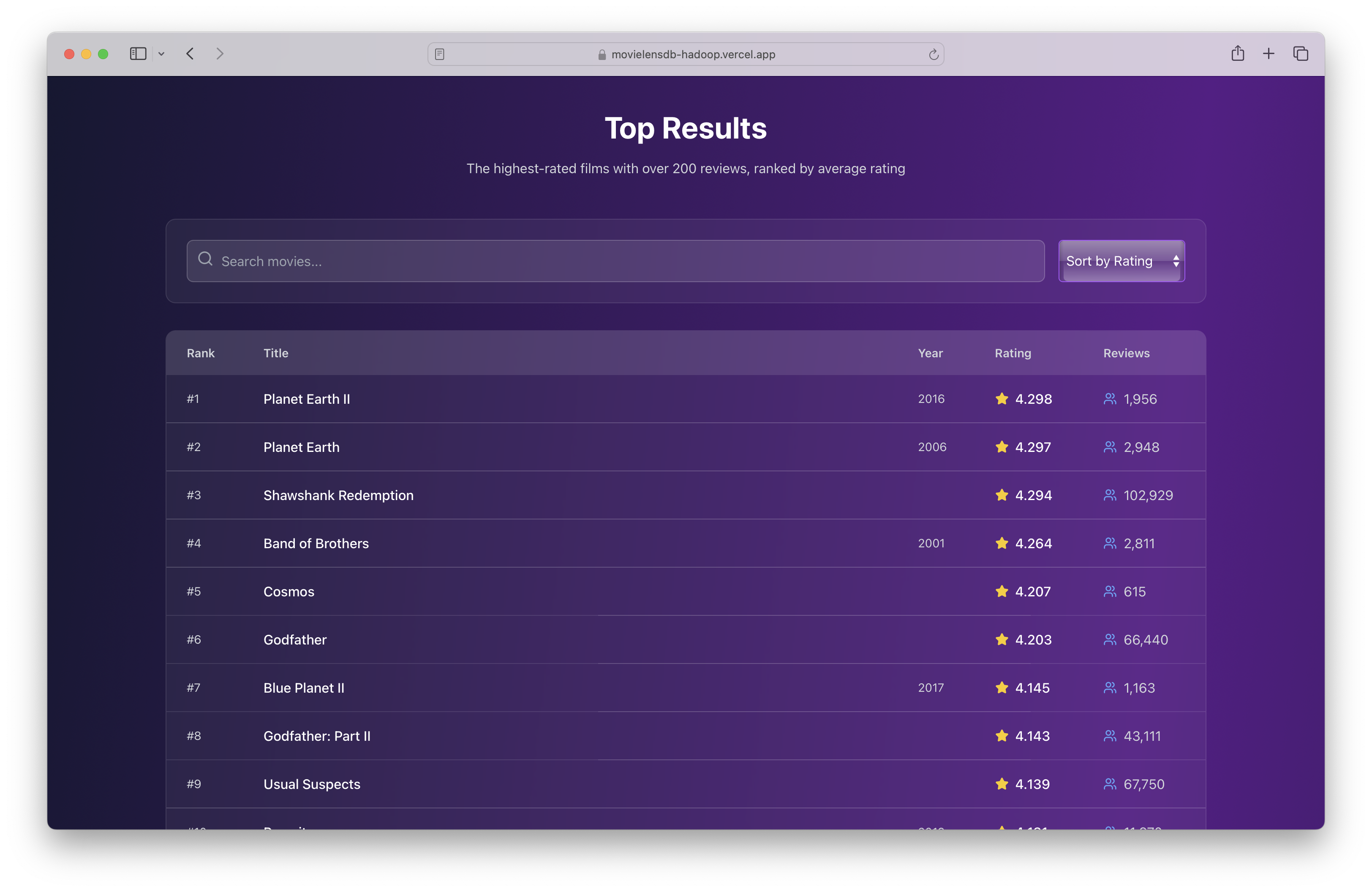
Results Site
— This was my kind of weekend. Good data, a few sparks of engineering curiosity, and now I finally have my own list of the people’s favorite movies. The final repository of code is here: https://github.com/Nikil-Shyamsunder/movielensdb-hadoop.
Enjoy Reading This Article?
Here are some more articles you might like to read next: